Sound Recognition Using ML
This was the final partner project for Introduction to Scientific Computing and Machine Learning, where we built and evaluated machine learning models to classify spoken digits and speaker gender from audio data.
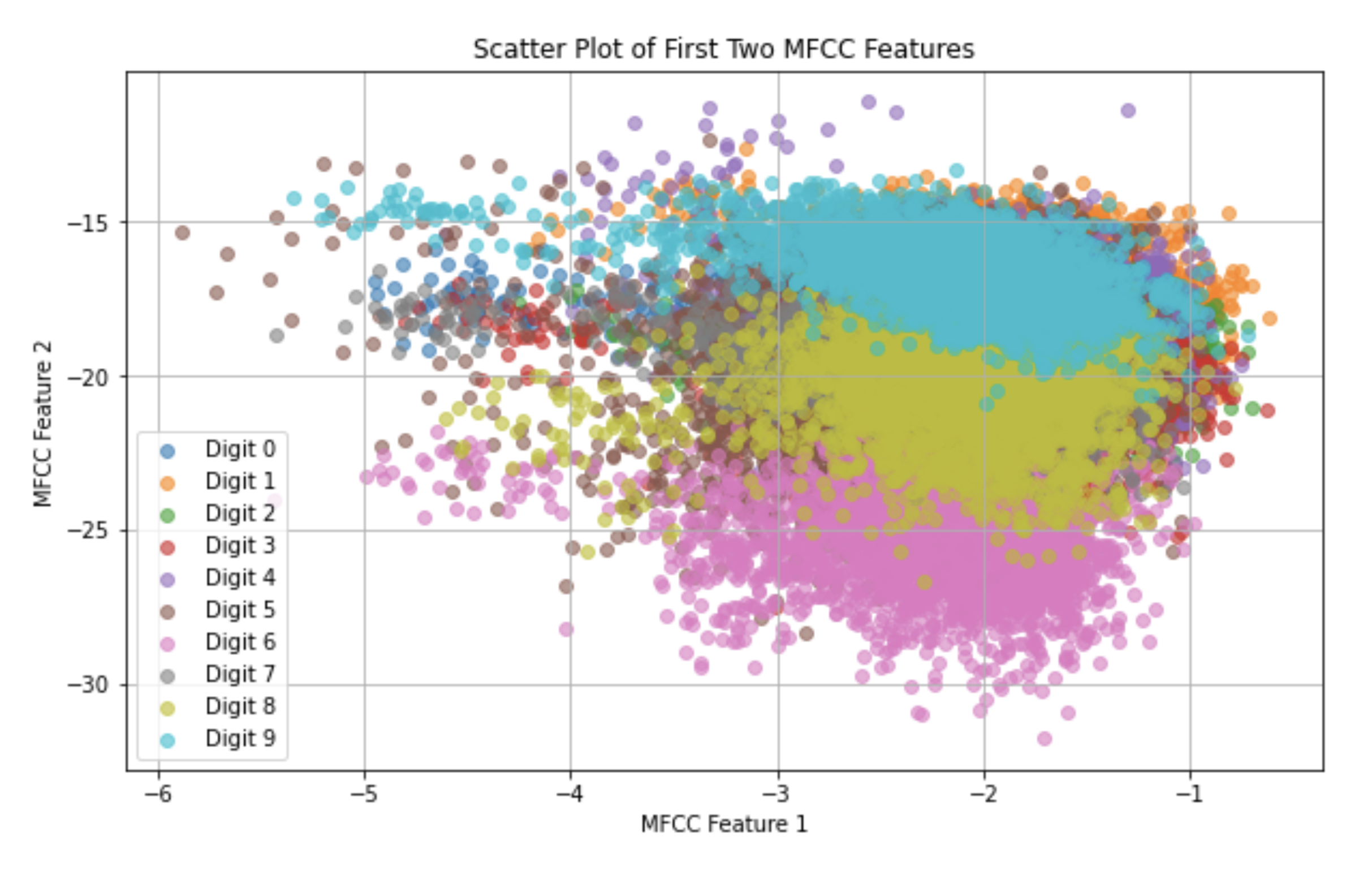
Overview
Using the AudioMNIST dataset, we developed a pipeline to classify spoken digits (0–9) and identify speaker gender based on Mel Frequency Cepstral Coefficient (MFCC) features. We trained and optimized five machine learning models—kNN, SVM, Logistic Regression, Random Forest, and Naive Bayes—using cross-validation and grid search. SVM achieved the best balance of accuracy and generalization, with over 81% test accuracy on digit classification.
Process
In this project, my teammate and I built a full audio classification pipeline using the AudioMNIST dataset, which contains 30,000 audio samples of spoken digits (0–9) from 60 different speakers. Our goal was twofold: first, to classify which digit was spoken in each audio clip, and second, to predict the speaker’s gender.
We began by extracting meaningful features from the raw .wav files using Mel Frequency Cepstral Coefficients (MFCCs), which are widely used in speech recognition for capturing the shape of audio signals. After organizing the data into a structured DataFrame, we parsed the file names to label each sample with its corresponding digit and speaker information.
Next, we split the dataset into training and testing sets and trained five different machine learning models—k-Nearest Neighbors, Support Vector Machine (SVM), Logistic Regression, Random Forest, and Gaussian Naive Bayes. We used k-fold cross-validation and grid search to tune hyperparameters and ensure reliable performance metrics. While both SVM and kNN performed well, we selected SVM as our final model due to its robustness against overfitting and competitive accuracy.
Finally, we applied the same feature extraction process to a secondary task: gender classification. Because the dataset was imbalanced (more male speakers than female), we used the SMOTE technique to oversample the minority class. The result was a well-generalized model with over 93% test accuracy for gender prediction—demonstrating the strength of a clean feature set and a thoughtful machine learning pipeline.
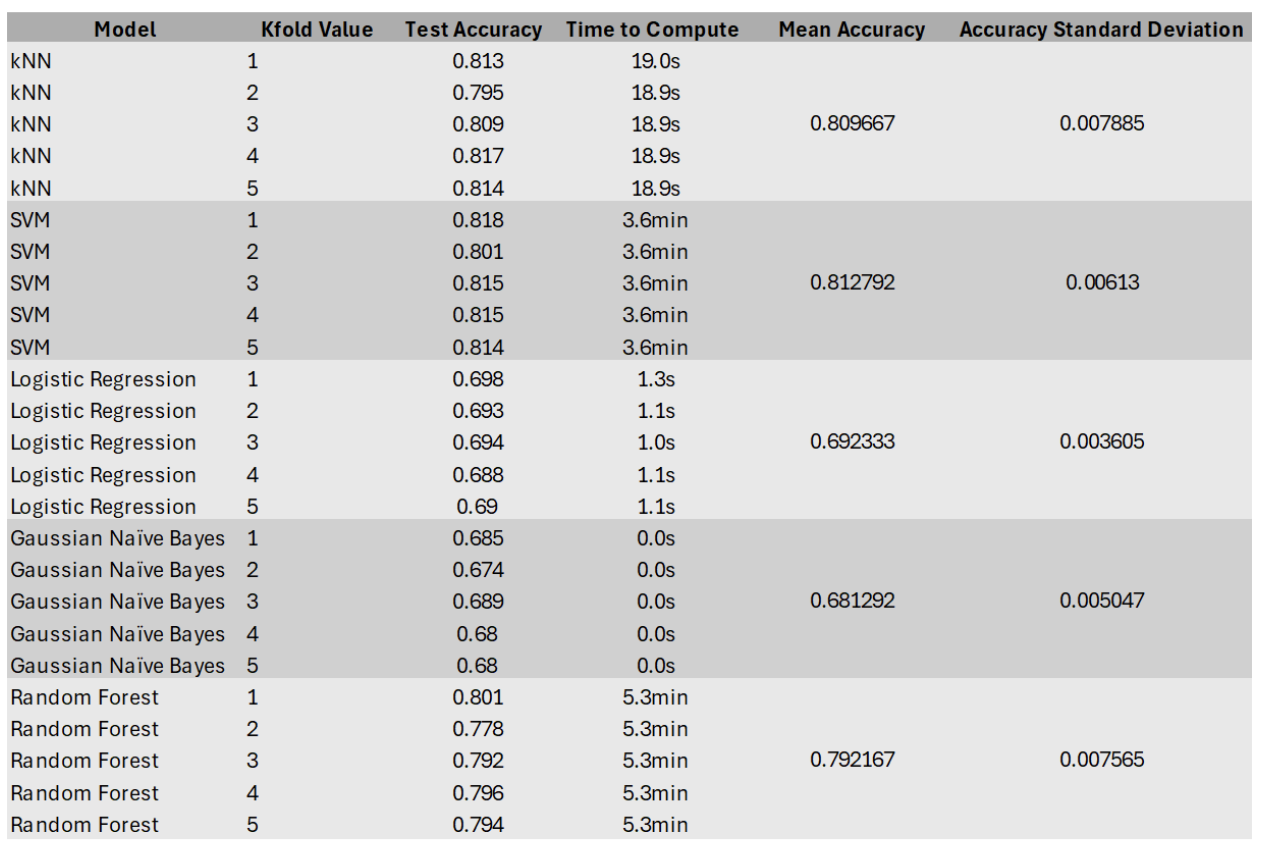
K-Fold cross-validation testing accuracy results for considered models.
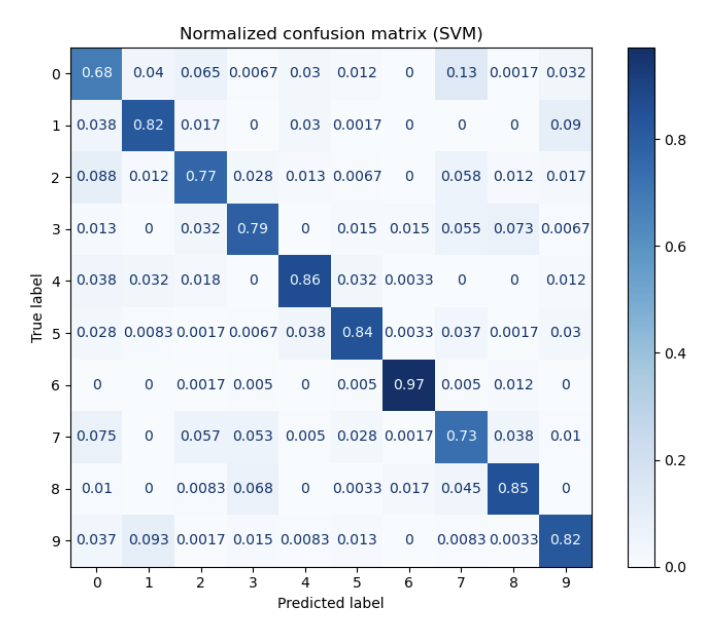
Normalized confusion matrix assessing the accuracy of SVM's predictions for each spoken digit